
Your AI Agent has an Amnesia Problem
What three conversations about memory engineering, context poisoning, and knowledge graphs taught me about why 95% of AI projects stall before production


Over the last few weeks on Chain of Thought, I've had three conversations that, taken together, changed how I think about why enterprise AI agents fail.
Michel Tricot, co-founder of Airbyte, showed me a live demo where a single Gong query burned 30,000 extra tokens because the agent had no structured context layer. Richmond Alake, Director of AI Developer Experience at Oracle, walked me through how human memory maps onto agent architecture and argued that memory engineering deserves to be its own discipline. Sudhir Hasbe, President and CPO of Neo4j (episode coming soon), made the case that hallucinations are a data architecture problem, not a model problem, and that knowledge graphs are the fix most enterprises are missing.
Three different guests. Three different companies. The same conclusion: the model is almost never the bottleneck. The way we give it information is.
I want to pull these threads together because I think they form a single argument that most teams building agents are getting wrong.
A quiet failure mode

When I sat down with Michel, he was straight forward - we are poisoning our agents with too much context. Context poisoning: the idea is both straightforward and a bit unintuitive. Aren’t context windows improving? Don’t we want our agents to have more information?
The problems come in once you dig into how that data is managed. When an agent connects directly to APIs without an intermediary data layer, it drowns in irrelevant information. Rate limits force pagination. Pagination forces the agent to process everything sequentially. Token budgets explode. And the agent's reasoning degrades because it's spending capacity managing data access instead of actually thinking about your question.
Think about studying for an exam by reading every textbook in the library, or trying to cram last minute, versus having organized notes for the specific course. You get through the material slower, retain less, and half your mental energy would go to figuring out which books to pick up next, or how to structure the information. You’ve consumed all the information, you just can’t think clearly when you’re drowning in it.
Michel demoed this problem live for me. Same query, two approaches. With Airbyte's context store: 45 Gong calls retrieved in about a minute, reasonable tokens. Without it: the agent had to paginate through every call in the system because Gong's API doesn't support filtering by user. Three minutes. 30,000 extra tokens. And that was a simple lookup.
The scary part: unless they’re paying attention, teams often don't know this is happening. They see an agent that's slow or occasionally wrong and assume they need a better model. They don't. They need better plumbing.
Memory is architecture
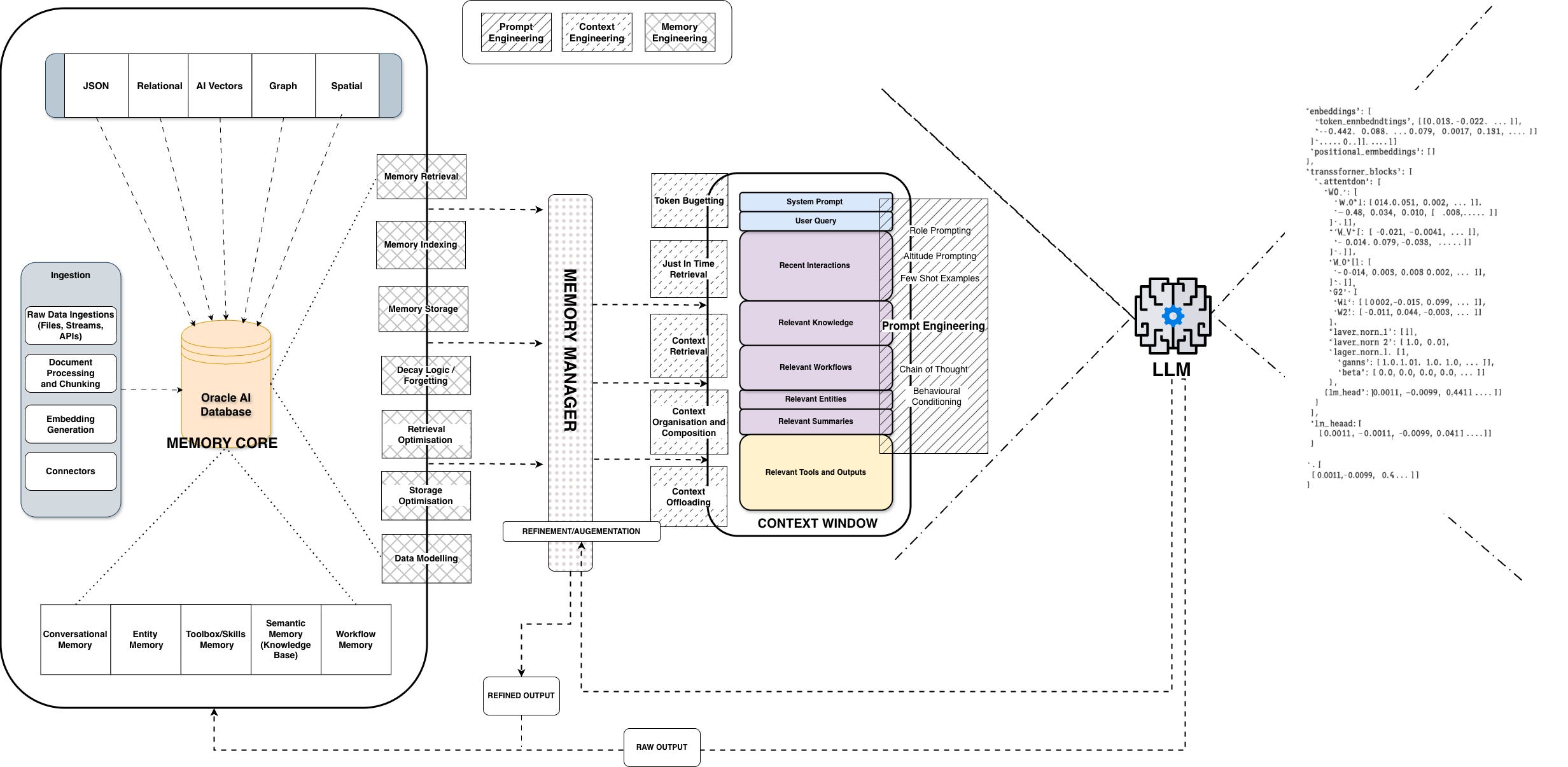
Richmond's expertise this week sharpened this idea even further. He argues that we've been through a progression, from prompt engineering (writing magic words) to context engineering (systematically selecting what goes into the context window) to what he calls memory engineering: designing how AI systems remember, forget, and adapt over time.
The distinction matters more than you might think. Context engineering is about what's in the window right now. Memory engineering is about what gets stored externally, how it's retrieved, and when it decays.
Richmond drew a direct parallel to neuroscience. Humans don't have one undifferentiated memory system. We have working memory (your context window), semantic memory (your knowledge base), episodic memory (timestamped interactions), and procedural memory (skills, routines). He built an agent, AFSA, that segments its context window to mirror these categories, and each memory type has its own retrieval logic and decay rules.
Two principles stood out. First: "think memory first." If you want an agent to perform well over long interactions or multi-session tasks, memory needs to be a first-class primitive in your architecture, not an afterthought bolted on when the context window fills up. Second, and this one stuck: "don't delete, forget." Information in a memory system should decay through relevance scoring, recency, and importance weighting. Not through hard deletes. The Stanford Generative Agents paper from 2023 formalized this with a weighted computation of recency, relevance, and importance that lets information naturally fade when it stops being useful.
This matters especially in regulated industries. If you hard-delete, you lose the audit trail. If you forget through decay scoring, the information is still recoverable when the compliance team comes knocking.
Mapping your knowledge with graphs
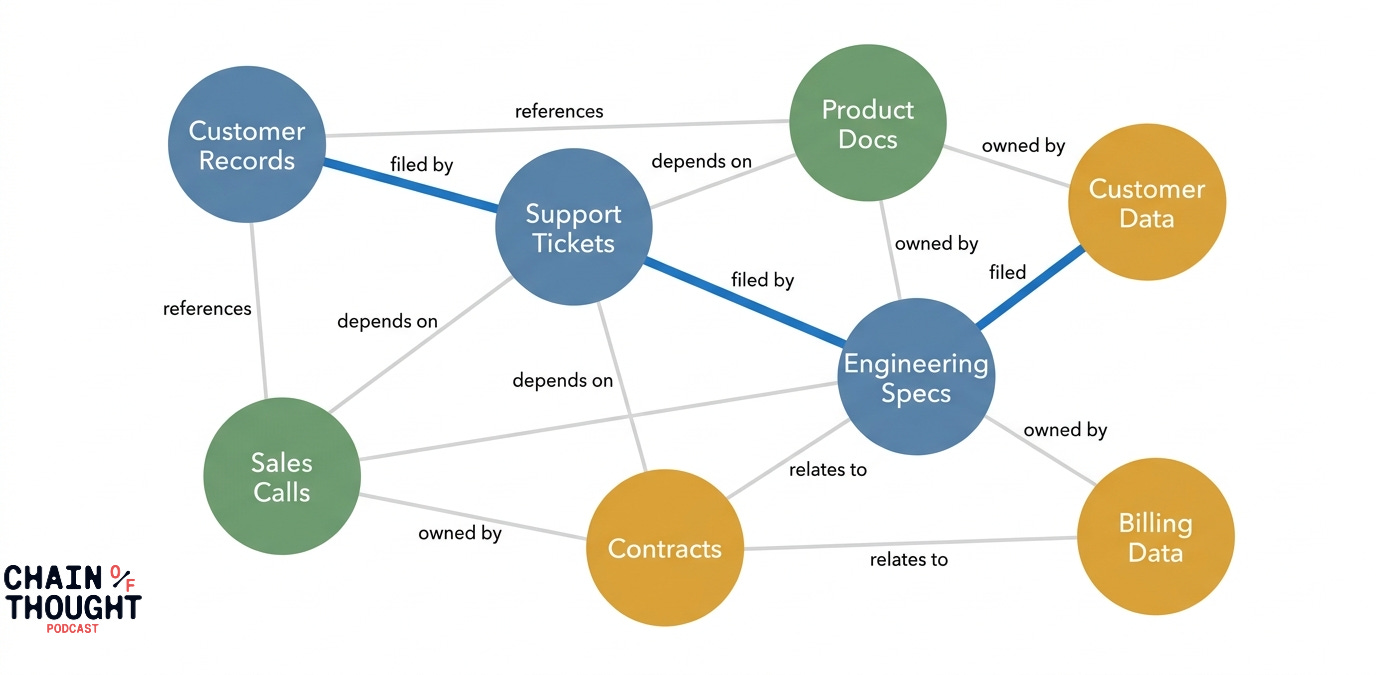
Sudhir Hasbe brought me the third piece. His argument: even if you nail context management and memory architecture, you still need a way to map the relationships between your enterprise data assets. Hence, knowledge graphs.
He gave an example from EA Sports. They have massive amounts of data in Snowflake, but when a user asks a business question, the agent needs to know which tables matter, what "FIFA" means in context (this year's game? last year's? the organization?), and how different data assets relate to each other. A knowledge graph sitting alongside the data lake acts as a semantic map, letting the agent reason about where to look before it starts querying.
This is why experience matters for us humans - we start to get a sense of what matters. We’ve made a map, and we’ve assigned mental ranks. We have a sense of where to look.
The accuracy numbers are striking for agents when their own information is graphed. Pure vector-based RAG typically lands around 60-65% accuracy for complex enterprise queries. Add a graph layer for metadata and relationships, and customers are getting above 90%. Add reasoning-engine tooling on top of that and you're pushing 95-97%.
This is also how humans operate. We are constantly building our own knowledge graphs, usually without thinking about it. Experience teaches us what matters and where to look. Companies formalize this as organizational memory—you may have heard it called “tribal knowledge.” Enterprise AI needs the same thing.
A fraud detection agent’s decisions need to be accessible to a customer service agent when someone calls asking why their transaction was blocked. That requires shared, structured memory across agents, not just individual agent state.
Fragmentation becomes the enemy.
The three layer data stack for agents
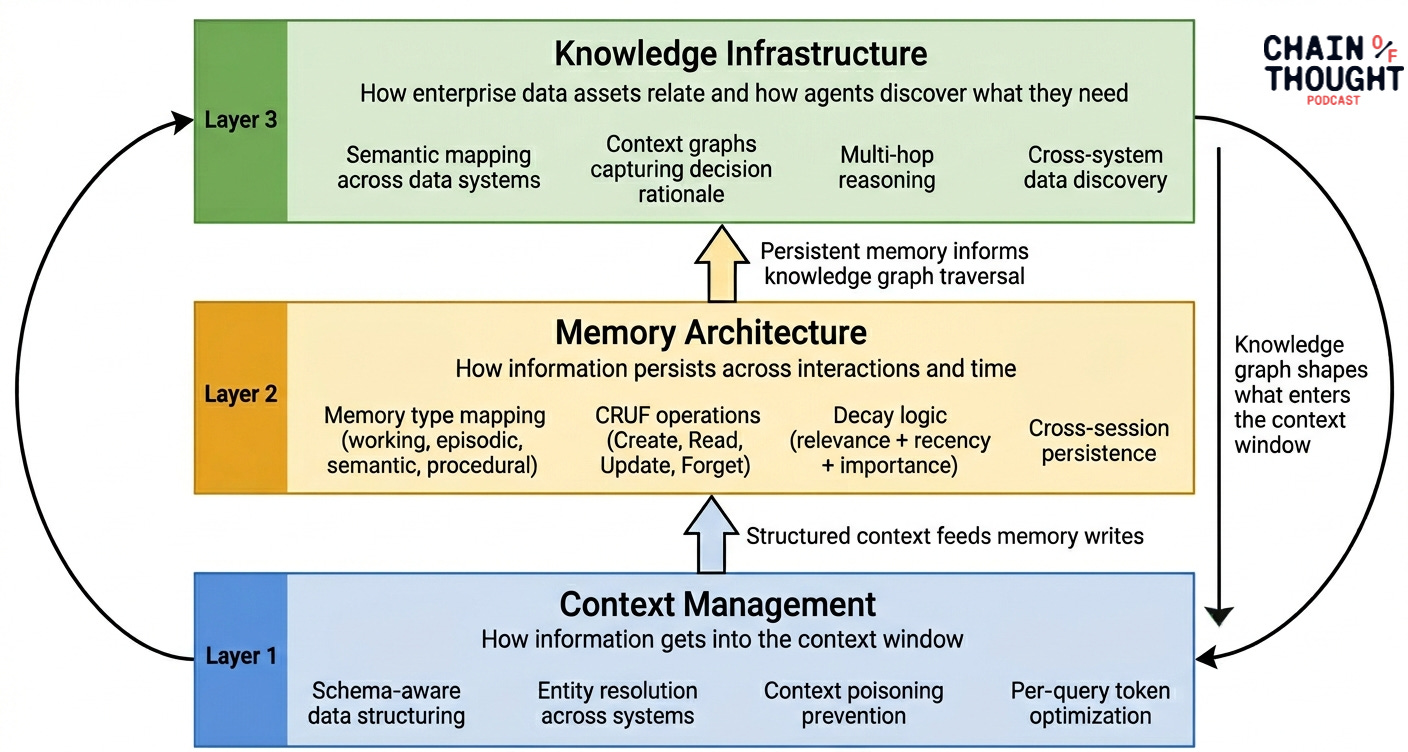
If you synthesize what I heard across these three conversations, a clear architecture emerges for your AI agents:
Layer 1: Context management. How information gets into the context window for any given query. This is what Michel's context store solves. Schema-aware, entity-resolved, pre-structured data that prevents context poisoning before it starts.
Layer 2: Memory architecture. How information persists across interactions, sessions, and time. This is Richmond's domain. Memory types mapped to cognitive functions, with CRUD operations (or CRUF, as Richmond joked, since you don't delete, you forget) and decay logic built into the agent harness.
Layer 3: Knowledge infrastructure. How enterprise data assets relate to each other and how agents discover what they need. This is Sudhir's knowledge graph layer. Semantic mapping, context graphs that capture decision rationale, and multi-hop reasoning across data that lives in dozens of systems.
The teams that are getting agent systems to production are building all three, and thinking deeply about how they interact.
Why This Matters Now
78% of enterprises have AI agent pilots. But a recent survey says only 14% have scaled one to production. Gartner thinks it’ll get worse before it gets better. They predicted last year that over 40% of agentic AI projects will be canceled by 2027. After these three conversations, I have a clearer theory about why.
The industry has been optimizing for model capability. Better reasoning, longer context windows, more parameters. Those improvements are real. But the gap between a model that can theoretically handle a million token context window and an agent that actually uses those tokens well is enormous. That gap is filled by context management, memory architecture, and knowledge infrastructure. The boring stuff. The plumbing.
As Richmond said: memory should be a first-class primitive, not an afterthought.
Yes, we need to engineer context for our agents. Yes, prompting can help.
But building evolving machines requires information retention. Structured memory. Persistent, and also designed to decay.
The teams that figure this out first will be the ones shipping agents that actually work. Everyone else will keep blaming the model.
This essay draws from three recent or upcoming Chain of Thought episodes:
Michel Tricot (Airbyte) on context poisoning and context stores
Richmond Alake (Oracle) on memory engineering as a discipline
Out this week and one of my favorites! Can’t recommend this episode enough. It’s what triggered this whole essay for me.
Sudhir Hasbe (Neo4j) on knowledge graphs for enterprise AI (coming soon)
Subscribe to get these conversations and more essays in your inbox.